
Or - OMG! My AWS free-tier is over in 2 months and there’s no way I’m paying monthly fees for almost idle machines!
A week or so ago, I suddenly realized that my AWS free-tier is about to expire in 2 months. I mainly use it for spot-instances that I take for a couple of hours to run some heavy calculations and to experiment with new AWS products. However, since a t1.micro machine was given for free, I always had one on and whenever I wanted just a small API for a project, I naturally used it. Some of those projects were neglected and one evolved to a non-commercial website, just for fun and my own experiment with tools and technologies. This is the Griddlers Ninja! website. (Griddlers = Nokogiri, Nonogram, שחור ופתור)
Griddlers Ninja! started as a small python project, just to visualize the process of solving a Griddlers board. When solving griddlers by hand, we tend to iterate rows and columns, looking for certain cells (black or white) and coloring them. This data helps us on the next iteration to color some more until the board is solved. I thought there was some ignored information here, and that’s the fact that after every iteration, we can calculate the probability of every cell to be black (based on the number of still-legal placements in which it is black out of the total number of legal placements for a given row). Using that, we can draw the board with grayscale colored cells and see how it evolves between iterations and whether we see the image ‘blurred’ after an iteration or two.
I’m not going to explain any further about the website itself, you can read some more and see a representation of the iterations here. This post will discuss the technical infrastructure behind the app and how I changed it so it will cost me fractions of the (relatively low) monthly price of t1.micro + smallest RDS instance.
Griddles Ninja old architecture
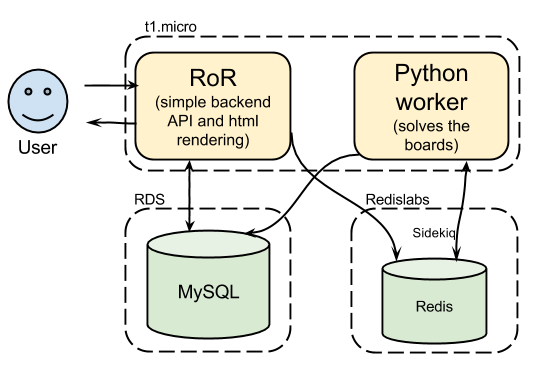
Pretty straight forward. I had the t1.micro machine so I used it to host a Ruby-On-Rails application that submitted jobs to Sidekiq for processing (solving boards) and also rendered HTMLs and persisted everything into a small MySQL instance.
As for costs (outside of free-tier):
- EC2 - $0.014/Hour => $10.08/Month (for a
t2.microinstance. they’ve upgraded since…) - RDS - $0.017/Hour => $12.24/Month
- Redis - FREE (Redislabs free tier)
- Total - $22.32/Month
Moving to a serverless architecture
I don’t take it personally, but let’s just say that traffic to the site doesn’t justify a 24x7 running server. My old Casio calculator can handle it and it’ll still be idle 50% of the time… While Rails generates HTML pages and handles regular traffic, the Python workers barely work at all (only when someone submits a new board). Since they are all served together by the same Burstable Performance instance, whenever a job comes in and the worker wakes up, it consumes all CPU credits pretty quickly and it may take hours to finish, by this time Rails is having troubles rendering pages as it doesn’t get enough CPU. In order to get rid of my EC2 machine, I had to move the frontend and the processing somewhere else.
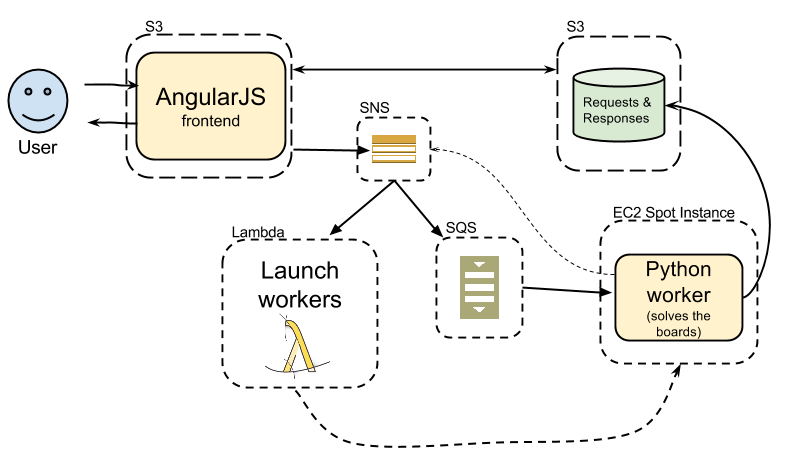
All code is in a GitHub repository.
Moving the frontend
That’s easy. It shouldn’t be served by Rails at all. I only put it there temporarily because it was a simple GUI and I suck at frontend technologies. I did, however, add AngularJS to my backlog. Months have passed, and I have finally found some time to see what is this marvelous piece of work everyone says that Google has put together. I won’t say I’m an Angular expert now, I’ve probably only touched the basics, and I can’t compare it to any of the other platforms simply because it’s my first JavaScript project. What I can say is that I don’t like JavaScript at all and that I had to use Google every 5 minutes just to find out that there is no library function for what I wanted to do and everyone on stackoverflow suggests that I add a method to Prototype for that. Ruby is much more fun!
Anyway, the whole frontend was moved to an AngularJS app which is stored and being served by S3 so it costs almost nothing. I didn’t even bother to add CloudFront to the mix because I trust you to keep the momentum by not generating a lot of traffic..
Getting rid of the backend (RoR)
Except for serving pages, the backend also handled all persistancy to the DB, and submitting the jobs. Not a very complex API.
It supports:
- Listing top solved boards (doesn’t even matter if these are the last-submitted or just random)
- Fetching results for an already solved board
- Submitting a new one
Since none of the data storage solutions is a pay-as-you-go only solution, I decided to use S3 as a key-value store for my requests and responses data. My luck here was that the API is really simple and I didn’t need any querying abilities. I also set a lifecycle policy on that bucket to automatically delete objects after a month, so I won’t accumulate any costs over time.
Triggering the workers is a different story, here I must have a queue that enforces single subscriber per message and is always up. SQS and SNS provide just that and don’t have any fixed fees. Messages can now pile up in the queue, but something needs to launch a worker to handle them. As you can guess, I’m not going to have a dedicated server for that, and actually - I want to get a decent server for the calculation phase while keeping my fees to the minimum.
By launching EC2 Spot Instances I could bid $0.03/Hour and get a m4.large machine (2 CPUs, 8GB) which is a huge improvement from the 5 minutes of CPU I was getting from the t1.micro machine before my credit ran out..
The SNS topic is the main hub here. There are two components that subscribe on that topic and get invoked when a new board is sent:
- The Python workers’ SQS queue (from which the workers get jobs)
- An AWS Lambda function that spins a worker if needed (actually - creates a spot instance request that will be fulfilled when the price is below my bid)
The Pros - Very cheap, and I don’t need to maintain almost anything…
The Cons - First, it’s not guarenteed that my worker machine will be launched. My bid (constant 3c/Hour) is over the market price at ~90% of the time. Second, it takes some time to boot the machine so if you are the first job in line, you’ll wait a bit more. Another thing is that I currently run only one worker (or none), so if there are multiple jobs, the others will have to wait.
The worker machine
My main concern was to keep booting time to a minimum while fetching the code dynamically from GitHub every time. I hate dealing with AMI images so I rather do it only once. I’ve installed all the big players on the AMI itself (python3.4, pip, ruby, and even compiled numpy as it takes a lot of time) and put a startup script that is run with the machine’s user-data that basically does git clone, pip install, bundle install and bundle exec ruby run.rb.
For queuing the SQS queue, I used Ruby just because I already have the code that handles the Python’s process STDOUT in Ruby from the previous version. I’ve changed it to use the AWS-SDK:
def poll
# visibility_timeout = 4 hours, idle_timeout = 10 minutes
poller.poll(visibility_timeout: 4*60*60, idle_timeout: 10*60) do |msg|
begin
logger.info "waiting for message..."
handle_message msg
rescue Exception => ex
logger.error "Error while handling message: #{ex.message}"
logger.error ex.backtrace.join "\n"
poller.change_message_visibility_timeout msg, 5 # return message to the queue (almost) immediately
throw :skip_delete
end
end
logger.info "Idle timeout passed. Quitting"
endThe poll function simply uses the QueuePoller object (poller variable) to poll the queue. The default visibility timeout for messages in this queue is 4 hours as it might take a lot of time to solve a very large board. If an error has occured, I don’t want to wait 4 hours to re-pull the message so I’m changing visibility timeout to 5 seconds and making sure the message isn’t deleted. When a message comes in, we call the handle_message function:
def handle_message(msg)
s3Location = JSON.parse(JSON.parse(msg.body)['Message'])
s3Location.delete :was_terminated # in case it's a resent message
termination_check_thread = Thread.new do
# this will return if termination was enforced (with ~2 minutes warning)
periodically_check_termination_time
sns.publish topic_arn: new_work_topic_arn, message: s3Location.merge({ was_terminated: true }).to_json
end
# read the request file from S3 and parse job parameters
# ...
# send the python job
core_path = "#{File.dirname(__FILE__)}/../core"
begin
status = Open4::popen4("#{core_path}/env/bin/python #{core_path}/bin/board_solver.py") do |pid, stdin, stdout, stderr|
stdin.puts(strategy)
stdin.puts(request_params)
stdin.puts(board)
stdin.close
result = stdout.read.strip
error = stderr.read.strip
end
# parse output
# ...
rescue Exception => ex
# handle exception (set output to an error object)
# ...
end
# upload output to S3 as response
# ...
termination_check_thread.raise 'stop:work_done'
endWhat’s important to understand here is that we must take care of the scenario where our machine is taken back by Amazon because our bidding price was too low. In this case, you have a 2 minutes termination notice to shut down your process gracefully. In my use-case, if that happens, the machine won’t finish solving the board and go down, but no one will ever launch a new spot request until another job comes in (Lambda does that, and it’s invoked by SNS). In order to solve that, I kept a thread polling the instance’s metadata every 5 seconds (the periodically_check_termination_time function) and when we’re about to go down, it publishes back a special message to the same SNS queue, causing the Lambda function to launch another spot instance request even though there is another one running (which is the one that is currently being terminated). This spot instance won’t be fulfilled immediately (we know that the market price went just above our bid) but it’ll stay there until price gets down again.
The Lambda function
The lambda function is spinning a worker machine if there isn’t already one running. It’s invoked whenever a message gets to the SNS queue and checks if there is another spot request open for the same app (or if it’s a ‘special message’) if there isn’t, it launches a new one. The code is pretty straight forward:
var aws = require('aws-sdk');
var Promise = require('bluebird');
var ec2 = new aws.EC2({apiVersion: '2015-04-15'});
Promise.promisifyAll(Object.getPrototypeOf(ec2));
var appName = 'MY-APP-NAME'
exports.handler = function(event, context) {
var message =JSON.parse(event.Records[0].Sns.Message);
console.log('Got the following work:', JSON.stringify(message));
// set user-data command for the worker (run the init script that is already on the image and shutdown when the polling service finishes)
userDataCommands = [
"#!/bin/bash",
"sudo su - app -c /etc/griddlers/app_init_script.sh",
"sudo shutdown -h now"
];
// look for spot requests that are open/active and with the same app's tag
descSpotInstanceParams = {
Filters: [
{ Name: 'state', Values: [ 'open', 'active' ] },
{ Name: 'tag:app', Values: [ appName ] }
]
};
// params for spot-instance-request
requestSpotInstancesParams = {
SpotPrice: '0.03',
InstanceCount: 1,
Type: 'one-time',
LaunchSpecification: {
ImageId: 'ami-XXXXXXX',
InstanceType: 'm4.large',
IamInstanceProfile: {
Name: 'griddlers_worker'
},
KeyName: 'MY-KEY-NAME',
Monitoring: {
Enabled: true
},
SecurityGroups: [
'enable-ssh-access'
],
UserData: new Buffer(userDataCommands.join("\n")).toString('base64')
}
}
// first check how many spot requests do we have at the moment
ec2.describeSpotInstanceRequestsAsync(descSpotInstanceParams)
.then(function(data) {
var spotInstanceRequestIds = data.SpotInstanceRequests.map(function(spr) {
return spr.SpotInstanceRequestId;
});
console.log("Got " + spotInstanceRequestIds.length + " spot instance request running: " + JSON.stringify(spotInstanceRequestIds));
if ((data.SpotInstanceRequests.length === 0) || (data.SpotInstanceRequests.length === 1 && message.was_terminated === true)) {
console.log("Requesting a new spot instance...");
return ec2.requestSpotInstancesAsync(requestSpotInstancesParams);
} else {
console.log("There are already spot instance running for application " + appName + " : " + JSON.stringify(spotInstanceRequestIds));
context.succeed();
throw "OK";
}
})
// avoid a race-condition if the spot request isn't created yet but we try to set tags on it (happened to me...)
.then(function(data) {
console.log("sleeping for 1 second to avoid race-condition with the creation of the spot instance request...");
return Promise.delay(1000).then(function() { return data });
})
// tag the spot request as our app
.then(function(data) {
console.log("Spot instances requested - " + data.SpotInstanceRequests[0].SpotInstanceRequestId);
return ec2.createTagsAsync( { Resources: [ data.SpotInstanceRequests[0].SpotInstanceRequestId ], Tags: [ { Key: 'app', Value: appName } ] } );
})
// that's it - done!
.then(function(data) {
console.log("Tag app:" + appName + " attached");
context.succeed();
})
.catch(function(err) {
// "OK" is thrown to break the then() chain in case that there are already enough running sprs
if (err === "OK") {
context.succeed();
} else {
context.fail("Error: " + JSON.stringify(err));
}
});
};Costs
I’ll calculate based on 10K hits per month and 500 job requests. Ye.. I’m laughing as well…
- S3
- Hosting and serving the AngularJS app (~3MB)
- Storage: ~$0.0
- Requests: $0.08 (I assumed 20 GETs per client)
- Data transfer: $2.7 (10K * 3MB = 30GB traffic out)
- Hosting the boards requests and responses (avg. request + response = 40KB)
- Storage: ~$0.0
- Requests: $0.08 (GET+PUT requests)
- Data transfer: $0.36 (based on 10 board views per user)
- Total: $3.22
- Hosting and serving the AngularJS app (~3MB)
- EC2
- $1.25 (spot instance bid of $0.03 * 5 minutes/Job)
- SNS/SQS
- $0.0 (No chance I’m going over 1M messages/Month…)
- Lambda
- $0.0 (Under 1M/Month)
- Total: $4.47
Pat on the back. A huge improvement! And don’t forget that assumes 10K visitors/Month and we all know that peace will come to the middle east before 10K people will use the Griddlers Ninja… Anyway, that saves me $17.85/Month or $214.2/Year. Here is a list of cool techie things you can buy with less than $200. I think I’ll choose something from there as a reward!
Future tasks
Currently, as this is a personal project, I didn’t create a CloudFormation template for this stack but as a best practice I can highly recommend that. When I do that, I’ll have to change some of the scripts to be easier to manipulate by an automated deployment process.